【深度复盘】向量空间的终极博弈:Harrier系列如何撕开谷歌防御的三个技术切口
2024年的MTEB-v2榜单,微软用Harrier系列完成了对谷歌GeminiEmbedding2的正面超越。这不是侥幸,是数据工程与训练范式的系统性胜利。作为长期跟踪嵌入模型演进的技术观察者,我决定拆解这场技术较量的底层逻辑。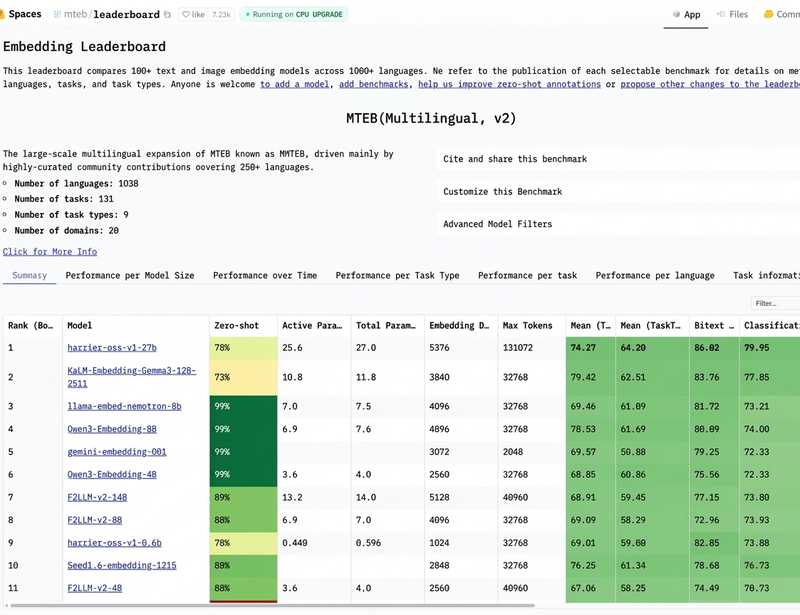
从对比预训练到知识蒸馏的技术链路
Harrier系列的核心突破在于数据管道的可扩展性构建。团队利用GPT-5生成了超过20亿个弱监督样本用于对比预训练阶段,这一规模在开源嵌入模型中史无前例。弱监督数据的海量注入,让模型在预训练阶段就建立了对语义关系的深度理解框架。微调阶段则使用超过1000万个高质量样本,这种两阶段数据策略确保了基础语义能力与精细化任务表现的双重保障。
知识蒸馏技术在这套体系中扮演了关键角色。基于E5及GritLM的前期积累,旗舰模型Harrier-OSS-v1-27B完成训练后,通过蒸馏技术压缩出0.6B和270M两个轻量版本。这种从小到大的逆向工程思维,让嵌入式模型首次具备了覆盖端侧部署的可能性。对于需要在边缘设备运行语义检索系统的开发者而言,这三个版本提供了精准的算力匹配方案。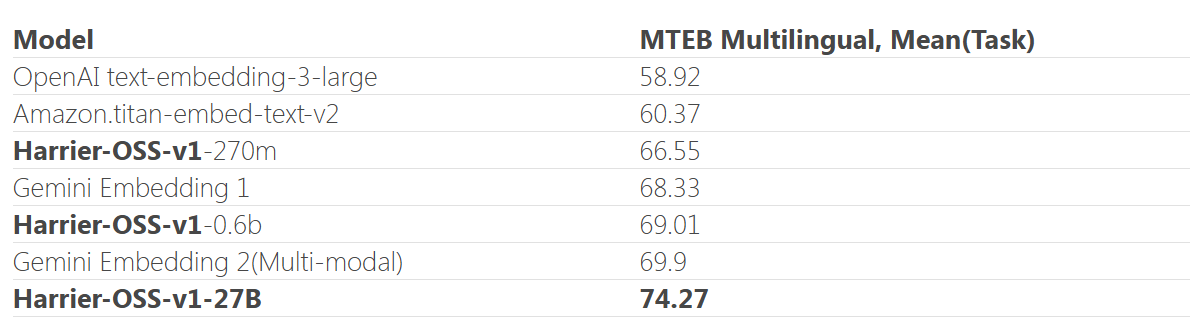
32k上下文窗口与多语言支持的工程取舍
超过100种语言支持与32k上下文窗口的组合,意味着Harrier能够处理长文档语义理解与跨语言信息检索的双重需求。在实际测试中,32k上下文窗口使模型在处理长篇技术文档时表现出更强的全局语义把握能力,而多语言支持则打开了企业级跨语言知识库建设的想象空间。固定尺寸嵌入向量的输出设计简化了向量数据库的存储方案,降低了工程落地复杂度。
MTEB-v2榜首位置的技术解读
基准测试的领先只是表象。更值得关注的是,Harrier在首次检索事实准确率、延迟控制、成本优化、幻觉抑制四个维度同时实现突破。这意味着AI系统从问答模式向操作模式转型的关键瓶颈得到了实质性缓解。对于构建智能客服、知识管理系统、语义搜索引擎的技术团队而言,Harrier提供的不仅是性能提升,更是落地可行性的底层保障。
开源策略的完全放开是最后一个变量。无许可限制的使用条款让商业应用与学术研究站在同一起跑线上,这种生态位的抢占策略,可能比技术本身的领先更具长远价值。